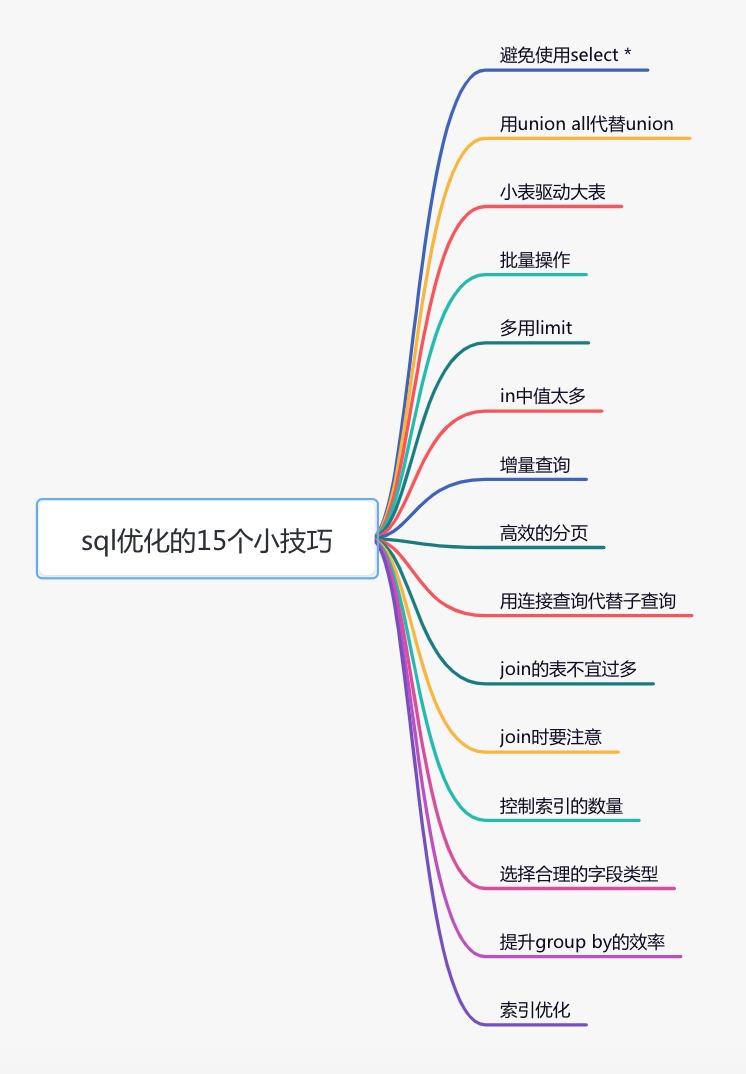
SQL優(yōu)化的這15招,真香!
當(dāng)前位置:點(diǎn)晴教程→知識(shí)管理交流
→『 技術(shù)文檔交流 』
前言sql優(yōu)化是一個(gè)大家都比較關(guān)注的熱門話題,無(wú)論你在面試,還是工作中,都很有可能會(huì)遇到。 如果某天你負(fù)責(zé)的某個(gè)線上接口,出現(xiàn)了性能問(wèn)題,需要做優(yōu)化。那么你首先想到的很有可能是優(yōu)化sql語(yǔ)句,因?yàn)樗母脑斐杀鞠鄬?duì)于代碼來(lái)說(shuō)也要小得多。 那么,如何優(yōu)化sql語(yǔ)句呢? 這篇文章從15個(gè)方面,分享了sql優(yōu)化的一些小技巧,希望對(duì)你有所幫助。
(我最近開(kāi)源了一個(gè)基于 SpringBoot+Vue+uniapp 的商城項(xiàng)目,歡迎訪問(wèn)和star。)[https://gitee.com/dvsusan/susan_mall] 1 避免使用select *很多時(shí)候,我們寫sql語(yǔ)句時(shí),為了方便,喜歡直接使用 反例: 在實(shí)際業(yè)務(wù)場(chǎng)景中,可能我們真正需要使用的只有其中一兩列。查了很多數(shù)據(jù),但是不用,白白浪費(fèi)了數(shù)據(jù)庫(kù)資源,比如:內(nèi)存或者cpu。 此外,多查出來(lái)的數(shù)據(jù),通過(guò)網(wǎng)絡(luò)IO傳輸?shù)倪^(guò)程中,也會(huì)增加數(shù)據(jù)傳輸?shù)臅r(shí)間。 還有一個(gè)最重要的問(wèn)題是: 那么,如何優(yōu)化呢? 正例: sql語(yǔ)句查詢時(shí),只查需要用到的列,多余的列根本無(wú)需查出來(lái)。 2 用union all代替union我們都知道sql語(yǔ)句使用 而如果使用 反例: 排重的過(guò)程需要遍歷、排序和比較,它更耗時(shí),更消耗cpu資源。 所以如果能用union all的時(shí)候,盡量不用union。 正例: 除非是有些特殊的場(chǎng)景,比如union all之后,結(jié)果集中出現(xiàn)了重復(fù)數(shù)據(jù),而業(yè)務(wù)場(chǎng)景中是不允許產(chǎn)生重復(fù)數(shù)據(jù)的,這時(shí)可以使用union。 3 小表驅(qū)動(dòng)大表小表驅(qū)動(dòng)大表,也就是說(shuō)用小表的數(shù)據(jù)集驅(qū)動(dòng)大表的數(shù)據(jù)集。 假如有order和user兩張表,其中order表有10000條數(shù)據(jù),而user表有100條數(shù)據(jù)。 這時(shí)如果想查一下,所有有效的用戶下過(guò)的訂單列表。 可以使用 也可以使用 前面提到的這種業(yè)務(wù)場(chǎng)景,使用in關(guān)鍵字去實(shí)現(xiàn)業(yè)務(wù)需求,更加合適。 為什么呢? 因?yàn)槿绻鹲ql語(yǔ)句中包含了in關(guān)鍵字,則它會(huì)優(yōu)先執(zhí)行in里面的 而如果sql語(yǔ)句中包含了exists關(guān)鍵字,它優(yōu)先執(zhí)行exists左邊的語(yǔ)句(即主查詢語(yǔ)句)。然后把它作為條件,去跟右邊的語(yǔ)句匹配。如果匹配上,則可以查詢出數(shù)據(jù)。如果匹配不上,數(shù)據(jù)就被過(guò)濾掉了。 這個(gè)需求中,order表有10000條數(shù)據(jù),而user表有100條數(shù)據(jù)。order表是大表,user表是小表。如果order表在左邊,則用in關(guān)鍵字性能更好。 總結(jié)一下:
不管是用in,還是exists關(guān)鍵字,其核心思想都是用小表驅(qū)動(dòng)大表。 4 批量操作如果你有一批數(shù)據(jù)經(jīng)過(guò)業(yè)務(wù)處理之后,需要插入數(shù)據(jù),該怎么辦? 反例: 在循環(huán)中逐條插入數(shù)據(jù)。 該操作需要多次請(qǐng)求數(shù)據(jù)庫(kù),才能完成這批數(shù)據(jù)的插入。 但眾所周知,我們?cè)诖a中,每次遠(yuǎn)程請(qǐng)求數(shù)據(jù)庫(kù),是會(huì)消耗一定性能的。而如果我們的代碼需要請(qǐng)求多次數(shù)據(jù)庫(kù),才能完成本次業(yè)務(wù)功能,勢(shì)必會(huì)消耗更多的性能。 那么如何優(yōu)化呢? 正例: 提供一個(gè)批量插入數(shù)據(jù)的方法。 這樣只需要遠(yuǎn)程請(qǐng)求一次數(shù)據(jù)庫(kù),sql性能會(huì)得到提升,數(shù)據(jù)量越多,提升越大。 但需要注意的是,不建議一次批量操作太多的數(shù)據(jù),如果數(shù)據(jù)太多數(shù)據(jù)庫(kù)響應(yīng)也會(huì)很慢。批量操作需要把握一個(gè)度,建議每批數(shù)據(jù)盡量控制在500以內(nèi)。如果數(shù)據(jù)多于500,則分多批次處理。 5 多用limit有時(shí)候,我們需要查詢某些數(shù)據(jù)中的第一條,比如:查詢某個(gè)用戶下的第一個(gè)訂單,想看看他第一次的首單時(shí)間。 反例: 根據(jù)用戶id查詢訂單,按下單時(shí)間排序,先查出該用戶所有的訂單數(shù)據(jù),得到一個(gè)訂單集合。 然后在代碼中,獲取第一個(gè)元素的數(shù)據(jù),即首單的數(shù)據(jù),就能獲取首單時(shí)間。 雖說(shuō)這種做法在功能上沒(méi)有問(wèn)題,但它的效率非常不高,需要先查詢出所有的數(shù)據(jù),有點(diǎn)浪費(fèi)資源。 那么,如何優(yōu)化呢? 正例: 使用
例如: 這樣即使誤操作,比如把id搞錯(cuò)了,也不會(huì)對(duì)太多的數(shù)據(jù)造成影響。 6 in中值太多對(duì)于批量查詢接口,我們通常會(huì)使用 sql語(yǔ)句如下: 如果我們不做任何限制,該查詢語(yǔ)句一次性可能會(huì)查詢出非常多的數(shù)據(jù),很容易導(dǎo)致接口超時(shí)。 這時(shí)該怎么辦呢? 可以在sql中對(duì)數(shù)據(jù)用limit做限制。 不過(guò)我們更多的是要在業(yè)務(wù)代碼中加限制,偽代碼如下: 還有一個(gè)方案就是:如果ids超過(guò)500條記錄,可以分批用多線程去查詢數(shù)據(jù)。每批只查500條記錄,最后把查詢到的數(shù)據(jù)匯總到一起返回。 不過(guò)這只是一個(gè)臨時(shí)方案,不適合于ids實(shí)在太多的場(chǎng)景。因?yàn)閕ds太多,即使能快速查出數(shù)據(jù),但如果返回的數(shù)據(jù)量太大了,網(wǎng)絡(luò)傳輸也是非常消耗性能的,接口性能始終好不到哪里去。 7 增量查詢有時(shí)候,我們需要通過(guò)遠(yuǎn)程接口查詢數(shù)據(jù),然后同步到另外一個(gè)數(shù)據(jù)庫(kù)。 反例: 如果直接獲取所有的數(shù)據(jù),然后同步過(guò)去。這樣雖說(shuō)非常方便,但是帶來(lái)了一個(gè)非常大的問(wèn)題,就是如果數(shù)據(jù)很多的話,查詢性能會(huì)非常差。 這時(shí)該怎么辦呢? 正例: 按id和時(shí)間升序,每次只同步一批數(shù)據(jù),這一批數(shù)據(jù)只有100條記錄。每次同步完成之后,保存這100條數(shù)據(jù)中最大的id和時(shí)間,給同步下一批數(shù)據(jù)的時(shí)候用。 通過(guò)這種增量查詢的方式,能夠提升單次查詢的效率。 8 高效的分頁(yè)有時(shí)候,列表頁(yè)在查詢數(shù)據(jù)時(shí),為了避免一次性返回過(guò)多的數(shù)據(jù)影響接口性能,我們一般會(huì)對(duì)查詢接口做分頁(yè)處理。 在mysql中分頁(yè)一般用的 如果表中數(shù)據(jù)量少,用limit關(guān)鍵字做分頁(yè),沒(méi)啥問(wèn)題。但如果表中數(shù)據(jù)量很多,用它就會(huì)出現(xiàn)性能問(wèn)題。 比如現(xiàn)在分頁(yè)參數(shù)變成了: mysql會(huì)查到1000020條數(shù)據(jù),然后丟棄前面的1000000條,只查后面的20條數(shù)據(jù),這個(gè)是非常浪費(fèi)資源的。 那么,這種海量數(shù)據(jù)該怎么分頁(yè)呢? 優(yōu)化sql: 先找到上次分頁(yè)最大的id,然后利用id上的索引查詢。不過(guò)該方案,要求id是連續(xù)的,并且有序的。 還能使用 需要注意的是between要在唯一索引上分頁(yè),不然會(huì)出現(xiàn)每頁(yè)大小不一致的問(wèn)題。 9 用連接查詢代替子查詢mysql中如果需要從兩張以上的表中查詢出數(shù)據(jù)的話,一般有兩種實(shí)現(xiàn)方式: 子查詢的例子如下: 子查詢語(yǔ)句可以通過(guò) 子查詢語(yǔ)句的優(yōu)點(diǎn)是簡(jiǎn)單,結(jié)構(gòu)化,如果涉及的表數(shù)量不多的話。 但缺點(diǎn)是mysql執(zhí)行子查詢時(shí),需要?jiǎng)?chuàng)建臨時(shí)表,查詢完畢后,需要再刪除這些臨時(shí)表,有一些額外的性能消耗。 這時(shí)可以改成連接查詢。 具體例子如下: 10 join的表不宜過(guò)多根據(jù)阿里巴巴開(kāi)發(fā)者手冊(cè)的規(guī)定,join表的數(shù)量不應(yīng)該超過(guò) 反例: 如果join太多,mysql在選擇索引的時(shí)候會(huì)非常復(fù)雜,很容易選錯(cuò)索引。 并且如果沒(méi)有命中中,nested loop join 就是分別從兩個(gè)表讀一行數(shù)據(jù)進(jìn)行兩兩對(duì)比,復(fù)雜度是 n^2。 所以我們應(yīng)該盡量控制join表的數(shù)量。 正例: 如果實(shí)現(xiàn)業(yè)務(wù)場(chǎng)景中需要查詢出另外幾張表中的數(shù)據(jù),可以在a、b、c表中 不過(guò)我之前也見(jiàn)過(guò)有些ERP系統(tǒng),并發(fā)量不大,但業(yè)務(wù)比較復(fù)雜,需要join十幾張表才能查詢出數(shù)據(jù)。 所以join表的數(shù)量要根據(jù)系統(tǒng)的實(shí)際情況決定,不能一概而論,盡量越少越好。 11 join時(shí)要注意我們?cè)谏婕暗蕉鄰埍砺?lián)合查詢的時(shí)候,一般會(huì)使用 而join使用最多的是left join和inner join。
使用inner join的示例如下: 如果兩張表使用inner join關(guān)聯(lián),mysql會(huì)自動(dòng)選擇兩張表中的小表,去驅(qū)動(dòng)大表,所以性能上不會(huì)有太大的問(wèn)題。 使用left join的示例如下: 如果兩張表使用left join關(guān)聯(lián),mysql會(huì)默認(rèn)用left join關(guān)鍵字左邊的表,去驅(qū)動(dòng)它右邊的表。如果左邊的表數(shù)據(jù)很多時(shí),就會(huì)出現(xiàn)性能問(wèn)題。
12 控制索引的數(shù)量眾所周知,索引能夠顯著的提升查詢sql的性能,但索引數(shù)量并非越多越好。 因?yàn)楸碇行略鰯?shù)據(jù)時(shí),需要同時(shí)為它創(chuàng)建索引,而索引是需要額外的存儲(chǔ)空間的,而且還會(huì)有一定的性能消耗。 阿里巴巴的開(kāi)發(fā)者手冊(cè)中規(guī)定,單表的索引數(shù)量應(yīng)該盡量控制在 mysql使用的B+樹(shù)的結(jié)構(gòu)來(lái)保存索引的,在insert、update和delete操作時(shí),需要更新B+樹(shù)索引。如果索引過(guò)多,會(huì)消耗很多額外的性能。 那么,問(wèn)題來(lái)了,如果表中的索引太多,超過(guò)了5個(gè)該怎么辦? 這個(gè)問(wèn)題要辯證的看,如果你的系統(tǒng)并發(fā)量不高,表中的數(shù)據(jù)量也不多,其實(shí)超過(guò)5個(gè)也可以,只要不要超過(guò)太多就行。 但對(duì)于一些高并發(fā)的系統(tǒng),請(qǐng)務(wù)必遵守單表索引數(shù)量不要超過(guò)5的限制。 那么,高并發(fā)系統(tǒng)如何優(yōu)化索引數(shù)量? 能夠建聯(lián)合索引,就別建單個(gè)索引,可以刪除無(wú)用的單個(gè)索引。 將部分查詢功能遷移到其他類型的數(shù)據(jù)庫(kù)中,比如:Elastic Seach、HBase等,在業(yè)務(wù)表中只需要建幾個(gè)關(guān)鍵索引即可。 13 選擇合理的字段類型
如果是長(zhǎng)度固定的字段,比如用戶手機(jī)號(hào),一般都是11位的,可以定義成char類型,長(zhǎng)度是11字節(jié)。 但如果是企業(yè)名稱字段,假如定義成char類型,就有問(wèn)題了。 如果長(zhǎng)度定義得太長(zhǎng),比如定義成了200字節(jié),而實(shí)際企業(yè)長(zhǎng)度只有50字節(jié),則會(huì)浪費(fèi)150字節(jié)的存儲(chǔ)空間。 如果長(zhǎng)度定義得太短,比如定義成了50字節(jié),但實(shí)際企業(yè)名稱有100字節(jié),就會(huì)存儲(chǔ)不下,而拋出異常。 所以建議將企業(yè)名稱改成varchar類型,變長(zhǎng)字段存儲(chǔ)空間小,可以節(jié)省存儲(chǔ)空間,而且對(duì)于查詢來(lái)說(shuō),在一個(gè)相對(duì)較小的字段內(nèi)搜索效率顯然要高些。 我們?cè)谶x擇字段類型時(shí),應(yīng)該遵循這樣的原則:
還有很多原則,這里就不一一列舉了。 14 提升group by的效率我們有很多業(yè)務(wù)場(chǎng)景需要使用 通常它會(huì)跟 反例: 這種寫法性能不好,它先把所有的訂單根據(jù)用戶id分組之后,再去過(guò)濾用戶id大于等于200的用戶。 分組是一個(gè)相對(duì)耗時(shí)的操作,為什么我們不先縮小數(shù)據(jù)的范圍之后,再分組呢? 正例: 使用where條件在分組前,就把多余的數(shù)據(jù)過(guò)濾掉了,這樣分組時(shí)效率就會(huì)更高一些。
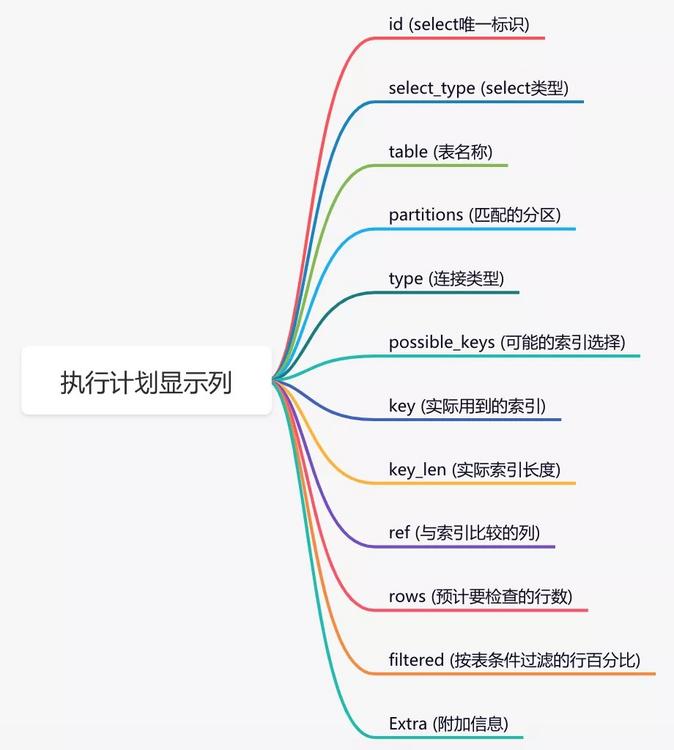
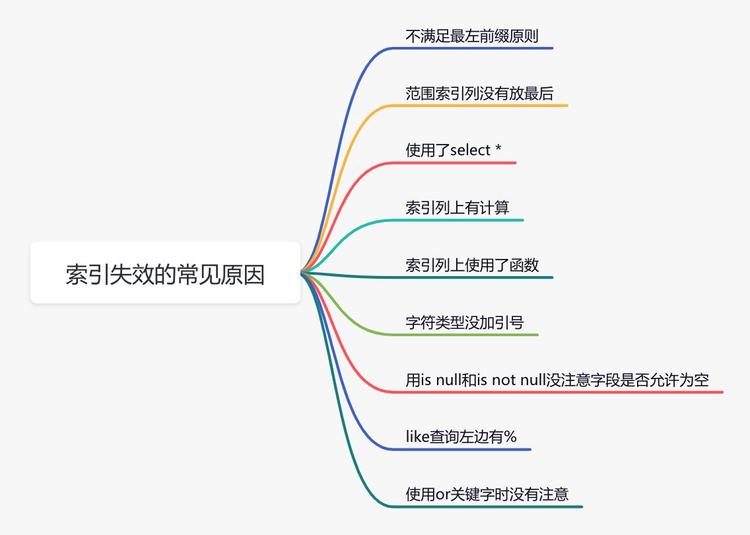
15 索引優(yōu)化sql優(yōu)化當(dāng)中,有一個(gè)非常重要的內(nèi)容就是: 很多時(shí)候sql語(yǔ)句,走了索引,和沒(méi)有走索引,執(zhí)行效率差別很大。所以索引優(yōu)化被作為sql優(yōu)化的首選。 索引優(yōu)化的第一步是:檢查sql語(yǔ)句有沒(méi)有走索引。 那么,如何查看sql走了索引沒(méi)? 可以使用 例如: 結(jié)果: 說(shuō)實(shí)話,sql語(yǔ)句沒(méi)有走索引,排除沒(méi)有建索引之外,最大的可能性是索引失效了。 下面說(shuō)說(shuō)索引失效的常見(jiàn)原因: 此外,你有沒(méi)有遇到過(guò)這樣一種情況:明明是同一條sql,只有入?yún)⒉煌选S械臅r(shí)候走的索引a,有的時(shí)候卻走的索引b? 沒(méi)錯(cuò),有時(shí)候mysql會(huì)選錯(cuò)索引。 必要時(shí)可以使用 轉(zhuǎn)自?https://www.cnblogs.com/12lisu/p/18654428 該文章在 2025/1/7 15:39:06 編輯過(guò) |
關(guān)鍵字查詢
相關(guān)文章
正在查詢... 晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開(kāi)發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫(kù)管理,保質(zhì)期管理,貨位管理,庫(kù)位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
晴公司官網(wǎng)")