[點晴永久免費OA]滴滴崩潰,損失幾個億的k8s 方案
當前位置:點晴教程→點晴OA辦公管理信息系統
→『 經驗分享&問題答疑 』
起因從震驚吃瓜開始從 2023 年 11 月 27 日晚上 10 點左右截止 2023 年 11 月 28 日中午 12 點期間,DD發生了長達12小時的p0級bug,造成的影響大家通過各種平臺或者親身經歷如何我就不多說了,單說對企業造成的損失超千萬單和超4個億的交易額。我只想說不愧是大企業,這也太狠了 簡單整理下崩潰原因DD自己在微博上說的是底層系統軟件發生故障,身為底層開發的我對此還是挺感興趣的,所以簡單吃了下瓜,網傳是滴滴未正常升級k8s導致集群崩潰,且由于集群規模過大(相信這么大規模集群一定跑著相當多的業務)導致造成影響肯定很大
DD在微博的致歉中說是底層系統軟件故障
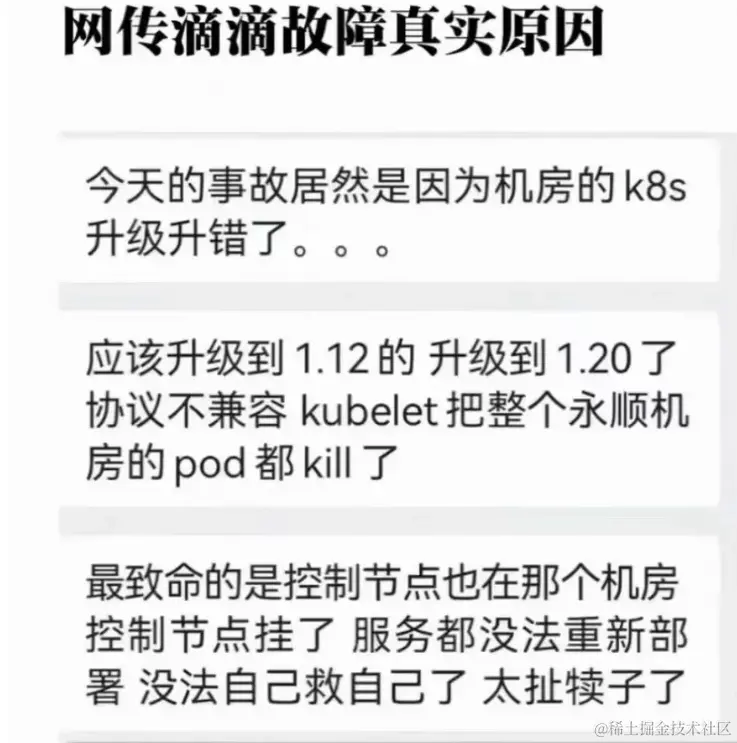
網傳是因為升級導致的故障 恰巧DD技術在公眾號上曾經發布過一篇# DD彈性云基于 K8S 的調度實踐文章,文章里介紹了他們選擇的升級方案,以及如此選擇升級方案的原因
DD的升級方案 dd 不愧是大廠,還有這么老版本的k8s集群,估計是很早就開始引入k8s集群了。通用的解決方案首先兩種方案的對比,DD已經在他們的技術文章中給明了優缺點,身為一個菜鳥我估計是不適合評論別人的方案,所以我只從我實際工作中遇到類似的問題是如何解決的, 問題一 集群規模過大 kubernetes 官方推薦了5000個node 上限,雖然并不代表超出上限一定會出問題,但是此次事故明顯告訴我們超出上限的集群一旦發生事故有多可怕了 通用的方案 實際生產環境當集群規模達到上限我們一般是怎么處理的呢,很簡單——聯邦集群,讓多個集群打通成聯邦集群,網絡和k8s資源互通,提高了業務容納的上限,同時將風險分攤給多個集群。增加了些許運維壓力,但是明顯要比瘋狂給單個集群加節點要安全多了 問題二 如何選擇升級方案 目前我遇到的大規模集群,基本上都是像dd 這樣選擇晚上的窗口期升級的,這點倒是沒什么可說的,但是很少有直接原地升級的,基本上都是有備份升級的,流量也不會直接全部涌入升級后的集群的,要經過逐步驗證才會切換到新集群的,原地升級我只能說是藝高人膽大了。 通用的方案 從dd 的技術博文上能猜出來,原地升級的方案肯定是經過他們內部驗證了,最起碼短期內是沒出問題,才敢拿到生產集群上實踐,但是很抱歉生產集群的扛風險能力還是太小了,所以還是建議老老實實選擇替換升級的方案吧 問題三多控制節點 最后一點就是網傳的控制節點崩潰的問題,我覺得這太離譜了,這種大廠應該知道多master 節點,以及master 不在同一機房的問題吧,不說多數據中心方案,基本的災備思想還是要有的吧 胡言亂語最近好像很多大廠的產品崩潰,先是阿里后是滴滴,加上最近的裁員潮,網上流出了很多笑話最知名的莫過 最后希望各位程序員技術越來越穩,默默奉獻的同時也能有自己的收獲 作者:萌萌醬 鏈接:https://juejin.cn/post/7306832876381437991 來源:稀土掘金 著作權歸作者所有。商業轉載請聯系作者獲得授權,非商業轉載請注明出處。 該文章在 2023/12/2 10:21:55 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886